
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 |
- python
- pandas
- 파이썬
- 직장인파이썬
- Firewall
- dataframe
- 라이브러리설치
- 고등퀀트
- 보조지표
- 주식투자
- 주가상승
- 변동성
- 퀀트투자
- 오라클
- 크롤링
- cloud
- 가치투자
- 함수
- 이동평균
- 개발자
- 클라우드
- 주가하락
- 오라클클라우드
- 차트분석
- 단기투자
- ubuntu
- 자동트윗
- 트위터
- 우분투
- Today
- Total
주경야매 미국주식
메이저리그 기록 크롤링 (baseball-reference.com) 본문
야구 데이터를 분석하고 싶다면 https://www.baseball-reference.com/ 은 각종 데이터의 보고다.
오늘은 이 사이트에서 류현진 선수의 기록을 크롤링해보자.
사이트에 접속한 뒤 류현진 선수의 이름으로 검색해도 되고, 다음 링크를 이용해도 된다.
https://www.baseball-reference.com/players/r/ryuhy01.shtml

스크롤바를 아래로 조금 내리면 투수로서의 류현진 선수의 기록이 나온다.


원하는 기록이 있는 테이블을 콕 집어서 크롤링하면 되는데, 여기에서는 Standard Pitching에 있는 기록을 가져와보겠다.
코드 구조를 파악하기 위해 마우스 우클릭 - 검사를 클릭해 개발자 화면을 연다.

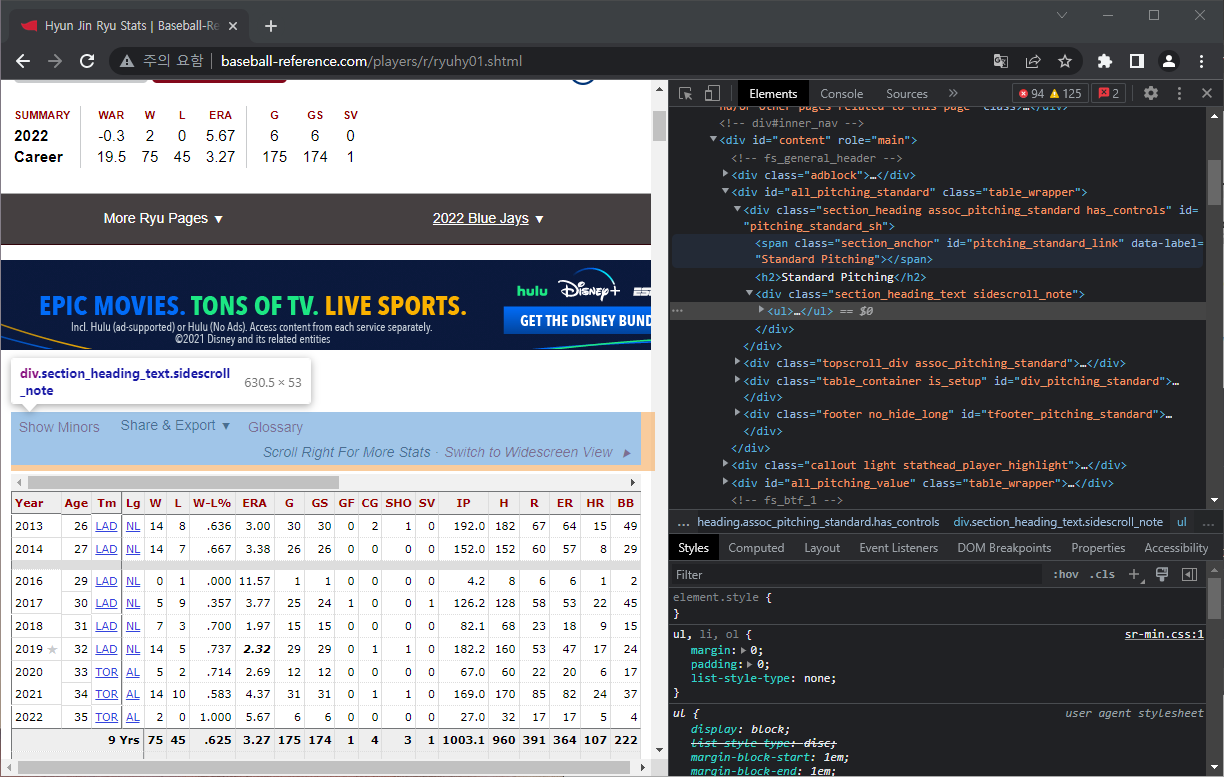
우선 Standard Pitching 테이블이 담긴 부분의 코드를 찾아가야 한다.
테이블의 가장 윗 부문에 마우스를 가져가 우클릭 - 검사를 클릭하면, 오른쪽 개발자 화면에 현재 마우스가 있는 부분의 코드가 표시된다. 아래 화면에서는 테이블 맨 위의 Year에서 우클릭 - 검사 를 클릭했고, 오른쪽에서 <th> 태그 부분이 해당 코드다.

표시된 <th> 태그 바로 위쪽에 <table> 태그가 보인다. 이 코드가 바로 Standard Pitching 테이블이 시작되는 부분이니, 여기서부터 작업을 시작하면 되겠다.
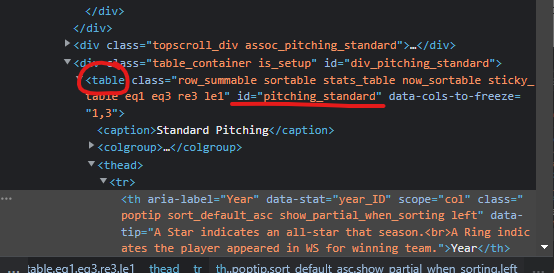
이 테이블의 id는 pitching_standard로 표시돼있다. id를 이용해서 테이블 안의 내용을 가져올 수 있다.
이제 코딩에 들어가 보자.
우선 웹사이트의 데이터를 끌어오는 requests, 가져온 데이터를 분석하는 BeautifulSoup 라이브러리를 호출한다.
import requests
from bs4 import BeautifulSoup이제 웹사이트의 소스코드를 끌어와 해석해준다.
url = 'https://www.baseball-reference.com/players/r/ryuhy01.shtml'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')2행에서 get 방식으로 소스코드를 가져왔고, 3행에서 BeautifulSoup에 넣어 소스코드를 해석해준다. 이제 soup에는 페이지의 소스를 해석한 내용이 들어있다. 이 중에서 Standard Pitching 테이블의 내용만 발라낸다.
soup.find('table', id='pitching_standard')</table class="row_summable sortable stats_table" data-cols-to-freeze="1,3" id="pitching_standard">
~~
find 명령어를 이용해 soup 내의 table 태그중 id='pitching_standard' 값을 찾으면 Standard Pitching 테이블을 구성하는 코드를 발라낼 수 있다. 여기까지 했으면 이제 다시 웹사이트로 돌아가서 가지고 올 기록을 선택해보자.
Standard Pitching 테이블에는 여러 기록들이 들어있는데, 그 중 승(W), 패(L), 방어율(ERA) 값을 가져와보자.
이전과 마찬가지로 해당 레코드 위에 마우스를 가져다 놓고 우클릭 - 검사를 클릭하면 가리키고 있는 코드 부분이 표시된다. 아래 화면은 ERA를 가리키는 소스코드다.
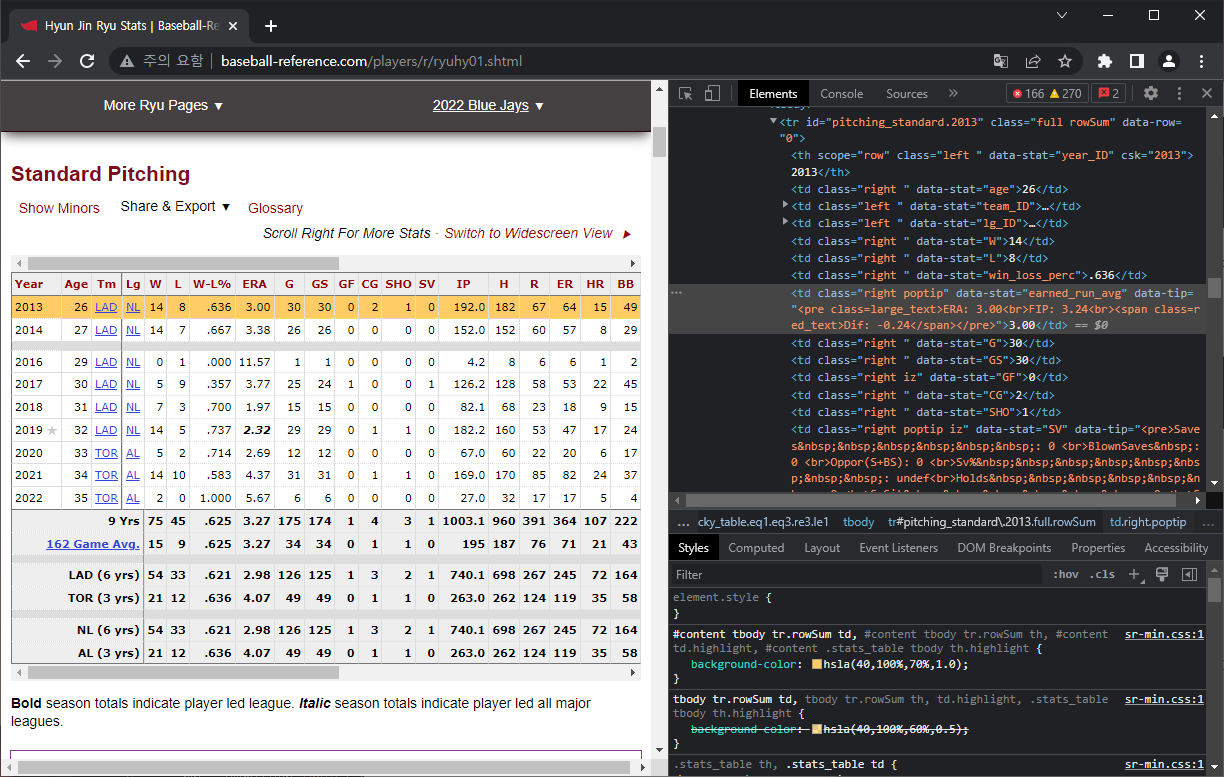
코드를 살펴보면 <td> 태그들이 각 데이터를 표시하고 있고, 데이터마다 data-stat이라는 변수에 이름이 지정되어있다. ERA의 경우 data-stat="earned_run_avg" 라고 되어있다. 이를 이용해 ERA 데이터를 콕찝어서 가져올 수 있다.
soup.find('table', id='pitching_standard').find_all(attrs={'data-stat':'earned_run_avg'})[<th aria-label="Earned Run Average" class=" poptip sort_default_asc hide_non_quals center" data-filter="1" data-name="Earned Run Average" data-stat="earned_run_avg" data-tip="<strong>9 * ER / IP</strong><br>For recent years, leaders need 1 IP<br>per team game played.<br>Bold indicates lowest ERA using current stats<br><span class=glimmer>Gold</span> means awarded ERA title at end of year." scope="col">ERA</th>,
~~
<td class="right " data-stat="earned_run_avg">2.98</td>,
<td class="right " data-stat="earned_run_avg">4.07</td>]
처럼 하면 된다. 그런데 위 결괏값은 html 코드까지 함께 있어서 보기에 편치 않다. 우리가 갖고 싶은 건 데이터뿐인데. 그래서 이번에는 데이터만 추출하도록 위 코드를 살짝 변형시켜보자.
데이터만 추출해내려면 테이블을 한 줄씩 읽어오는게 편하다. 테이블에서 줄을 표현하는 태그는 <tr>이다. <tr> 태그를 순회하며 한줄씩 읽어보자.
for p in soup.find('table', id='pitching_standard').find('tbody').find_all('tr'):
print(p.find(attrs={'data-stat':'earned_run_avg'}).text)
3.00
3.38
~~
5.67
1행은 테이블에서 <tr> 태그들을 find_all로 찾아내 이들을 순회한다. 각 행은 p라는 변수에 담는다.
2행은 각 행을 나타내는 p에서 data-stat='earned_run_avg'인 태그를 찾아 그 값을 출력한다.
다른 데이터도 같은 방식으로 가져올 수 있다. 이제 W, L, ERA 데이터를 한 번에 가져와 딕셔너리에 저장해서 출력해본다.
pitching = {}
pit = soup.find('table', id='pitching_standard').find('tbody').find_all('tr')
for p in pit:
pdata = {}
pdata['W'] = p.find(attrs={'data-stat':'W'}).text
pdata['L'] = p.find(attrs={'data-stat':'L'}).text
pdata['ERA'] = p.find(attrs={'data-stat':'earned_run_avg'}).text
pitching[p.find(attrs={'data-stat':'year_ID'}).text] = pdata
pitching{'': {'ERA': '', 'L': '', 'W': ''},
'2013': {'ERA': '3.00', 'L': '8', 'W': '14'},
'2014': {'ERA': '3.38', 'L': '7', 'W': '14'},
'2016': {'ERA': '11.57', 'L': '1', 'W': '0'},
'2017': {'ERA': '3.77', 'L': '9', 'W': '5'},
'2018': {'ERA': '1.97', 'L': '3', 'W': '7'},
'2019': {'ERA': '2.32', 'L': '5', 'W': '14'},
'2020': {'ERA': '2.69', 'L': '2', 'W': '5'},
'2021': {'ERA': '4.37', 'L': '10', 'W': '14'},
'2022': {'ERA': '5.67', 'L': '0', 'W': '2'}}
1행은 가져온 데이터를 담을 딕셔너리 pitching을 만들어둔다.
2행에서 각 줄을 순환하도록 <tr>을 찾아 pit에 담아두고,
3행에서 각 줄을 순회하며,
4행에서는 줄 별 데이터를 담을 pdata 딕셔너리를 만들고,
5~7행은 각각 W, L, ERA 데이터를 가져와 pdata에 각각의 이름으로 담는다.
8행은 줄의 데이터를 담은 딕셔너리를 전체 딕셔너리인 pitching에 옮겨 담는다. pdata 딕셔너리는 매 줄마다 데이터를 업어치기 때문에 다음 줄이 되면 사라진다. 그전에 pitching으로 옮겨 담아야 한다.
마지막 줄에서는 pitching 딕셔너리에 저장된 값을 출력해본다.
지금까지 https://www.baseball-reference.com/ 에서 메이저리그 선수 기록 데이터를 가져오는 방법을 알아봤다.

'파이썬' 카테고리의 다른 글
| 폐쇄망에 파이썬 및 라이브러리 설치 (1) | 2022.09.17 |
|---|---|
| 텔레그램 봇 메시지 보내기 (2) | 2022.09.17 |
| 구글 뉴스 크롤링 (126) | 2022.07.04 |
| 파이썬의 클래스 (1) | 2022.06.22 |
| 파이썬의 함수 (0) | 2022.06.22 |



