
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 오라클클라우드
- 오라클
- ubuntu
- 고등퀀트
- 주가하락
- 차트분석
- 퀀트투자
- 트위터
- 단기투자
- 주식투자
- 보조지표
- 주가상승
- 변동성
- 이동평균
- 파이썬
- 클라우드
- 함수
- pandas
- 라이브러리설치
- 크롤링
- dataframe
- 가치투자
- 직장인파이썬
- 개발자
- Firewall
- cloud
- python
- 우분투
- 자동트윗
- Today
- Total
주경야매 미국주식
구글 뉴스 크롤링 본문
구글 뉴스를 크롤링 해보자.
'nft nyc 2022 after party' 라는 키워드로 구글링한 후, 뉴스탭으로 이동해 이 키워드로 검색되는 뉴스의 제목과 링크를 크롤링 하겠다.
검색은 크롬 브라우저를, 코딩은 구글 콜랩(https://colab.research.google.com/)을 사용한다.
구글 검색창에 'nft nyc 2022 after party'를 넣고 구글링한 후 뉴스탭으로 이동한다.
크롤링을 하려면 우선 대상 사이트의 구조를 파악해야 한다. 이를 위해 브라우저 빈 공간에서 마우스 우클릭을 하고 나타나는 팝업 메뉴에서 검사를 클릭한다.
브라우저 화면이 다음과 같이 바뀐다.
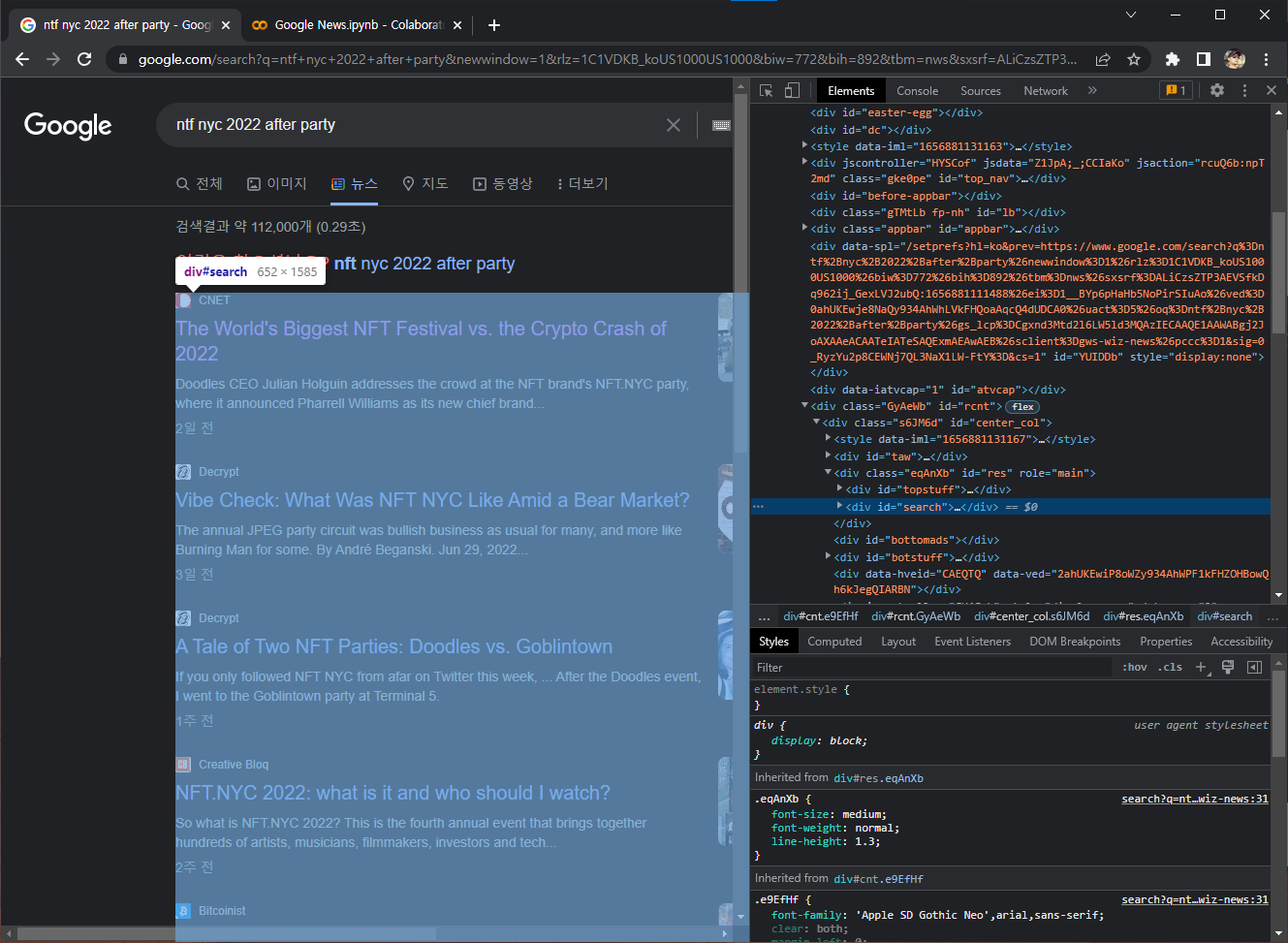
화면이 왼쪽과 오른쪽으로 분할되어 나오는데, 왼쪽은 원래 보고있던 검색결과가, 오른쪽에는 이 화면을 구성하는 소스코드가 보인다.
소스코드를 따라서 마우스를 이리저리 움직이다보면 위 화면과 같이 왼편의 검색결과화면 일부에 뿌연 음영이 표시되고, 마우스를 움직이면 음영이 따라서 움직인다. 이때 마우스가 올려진 곳이 바로 음영 부분을 구현한 코드다. 소스코드는 접었다▶ 펼쳤다▼ 할 수 있으므로 필요에 따라 펼쳐가며 내가 원하는 부분의 코드가 어디 있는지 찾을 수 있다.
우리 목표는 뉴스 검색결과에서 제목과 링크를 가져오는거다. 이를 위해 검색결과가 표현된 부분의 코드를 찾아보자.
구조를 파악하기 수월하려면 관심없는 부분은 최대한 빼고, 관심있는 부분에만 음영이 생기도록 소스코드를 잘 발라야 한다. 여기에서는 아래 코드로 둘러쌓인 부분이 바로 거기다.
<div id="search">
~~
</div>이제 봐야 할 소스코드를 뉴스검색 결과가 있는 영역으로만 한정했으니 분석이 좀 수월해졌다. <div id="search">옆의 ▶를 클릭해 펼쳐서 내부 코드로 들어가보자.

펼치다보니 <div class="xuvV6b" data-hvied 로 시작하는 비슷한 코드가 10개가 연달아 나오는 부분이 보인다. 이 코드를 따라 마우스를 움직이면 왼편 검색결과 화면의 각각의 결과를 따라 음영이 움직이는 것을 볼 수 있다. 즉, 이 코드 하나하나가 검색결과 하나씩을 나타낸다고 파악할 수 있다.
이번에는 최상위 검색결과를 따라 들어가보자. <div class="xuvV6b" 중 맨 위에 있는 코드를 열어본다.
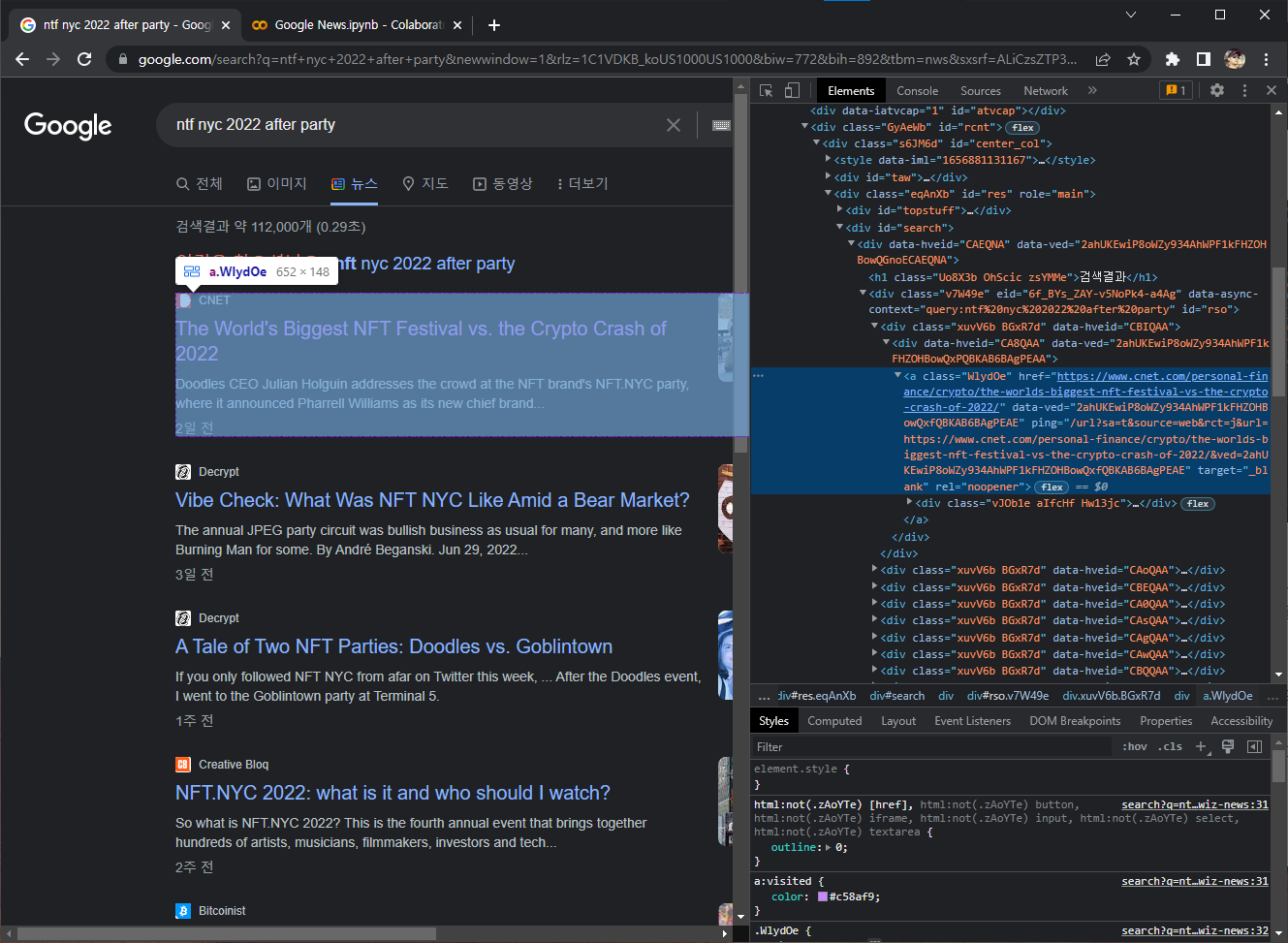
<a class="WlydOe" href="~~~ 로 시작하는 코드가 보인다. html에서 <a href="주소"> 태그는 하이퍼링크를 나타낸다. href에 담긴 주소가 우리가 찾는 링크 주소다. 그렇다. 링크를 찾은 것이다.
이번에는 제목을 찾아보자. 코드를 좀 더 펼쳐보자.
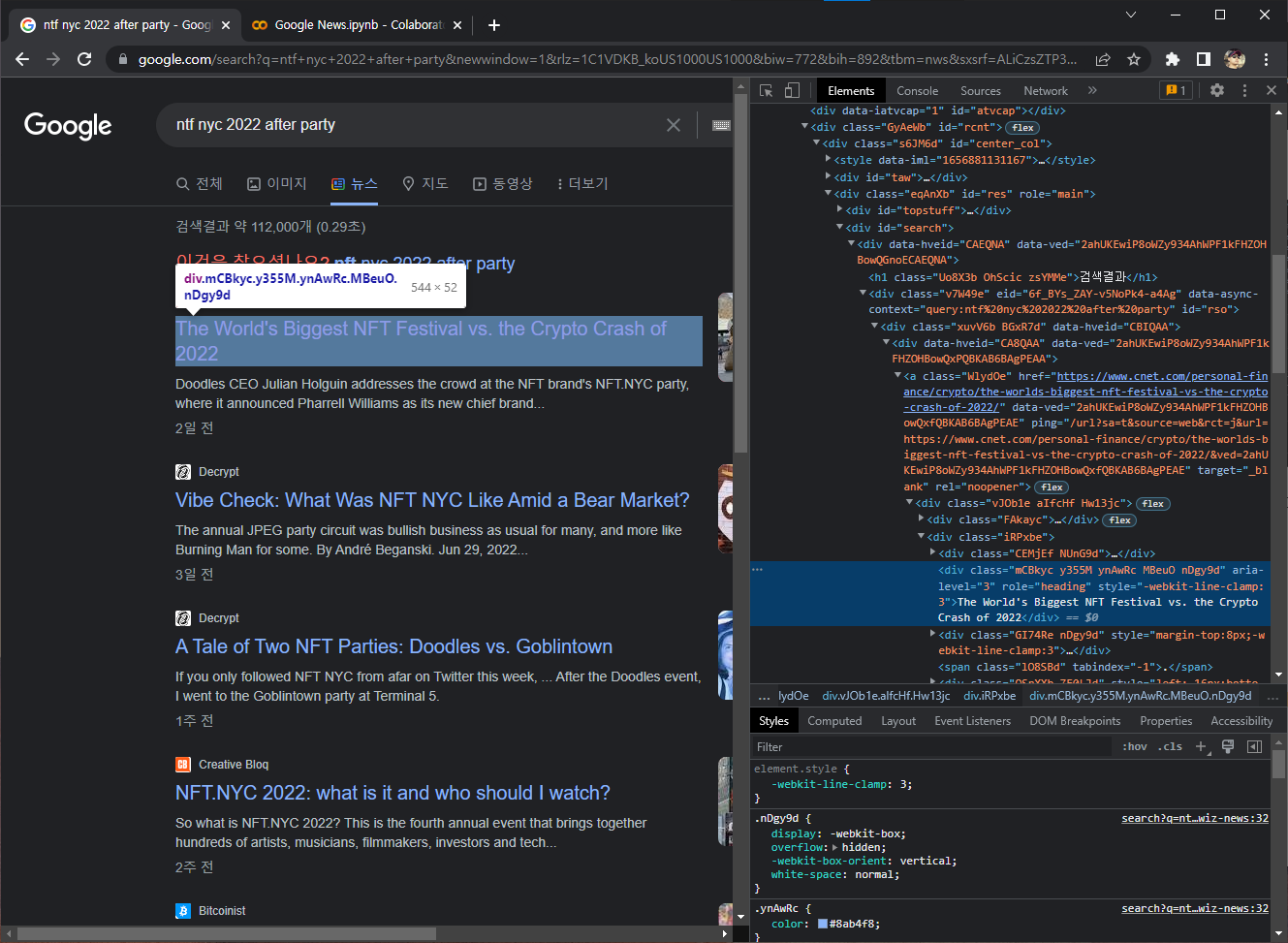
<div class="~" role="heading" ... 으로 표현된 코드 위에 마우스를 옮기니 왼편 검색결과에서 제목줄 만으로 음영 범위가 좁혀졌다. 즉, 이 부분이 뉴스 제목이라는 의미다.
이제 어떤 코드가 화면의 어떤 구성하는지 파악했으니 본격적인 코딩에 들어가보자.
브라우저에서 새 탭을 열고 구글 콜랩(https://colab.research.google.com/)에 접속해 파일 - 새 노트를 클릭한다.

파이썬 코딩을 할 수 있는 빈 노트북이 열렸다.
맨 윗줄에 다음 코드를 입력하고 Shift + Enter를 눌러 코드를 실행한다.
import requests
from bs4 import BeautifulSoup
크롤링의 첫 단계는 대상 화면의 코드를 긁어와 해석하는 것이다.
1행은 웹 상의 코드를 긁어오는 기능을 가진 requests 라이브러리를, 2행은 가져온 코드를 해석하는 BeautifulSoup 라이브러리를 사용할 수 있도록 준비한다.
이제 크롤링할 사이트를 지정할 차례. 아까 찾아놓은 검색결과 화면의 url을 복사해서 뜯어보자.
https://www.google.com/search?q=ntf+nyc+2022+after+party&newwindow=1&rlz=1C1VDKB_koUS1000US1000&biw=772&bih=892&tbm=nws&sxsrf=ALiCzsbDU3az5CAsV5pvxg4ArHDNVVkdfQ%3A1656943620275&ei=BPTCYq-dEKGliLMPuLi94Ak&ved=0ahUKEwivr5j_s9_4AhWhEmIAHThcD5wQ4dUDCA4&uact=5&oq=ntf+nyc+2022+after+party&gs_lcp=Cgxnd3Mtd2l6LW5ld3MQAzIECAAQE1AAWABgiwVoAHAAeACAAUOIAUOSAQExmAEAwAEB&sclient=gws-wiz-newshttps://www.google.com/search?... 뒤로 파라미터들이 길게 붙어있는데, 그 중 꼭 필요한 파라미터만 가져오면 된다. 어떤 파라미터가 꼭 필요한 건지 알려면 각 파라미터들을 하나씩 붙여 브라우저 주소창에 넣고 실행해 원하는 결과값이 나오는지 확인하는 것이다.
url에서 ?는 기본 주소와 파라미터 부분을 구분하는 기호이고, &는 각 파라미터를 구분하는 기호다.
즉, https://www.google.com/search 까지는 기본 주소이고, q가 첫번째 파라미터, newwindow는 두번째 파라미터다.
예를들어 맨 앞에 있는 q=ntf+nyc+2022+after+party 부분이 꼭 필요한지 확인 하려면 https://www.google.com/search?q=ntf+nyc+2022+after+party 까지만 주소창에 넣고 결과를 확인해본다.
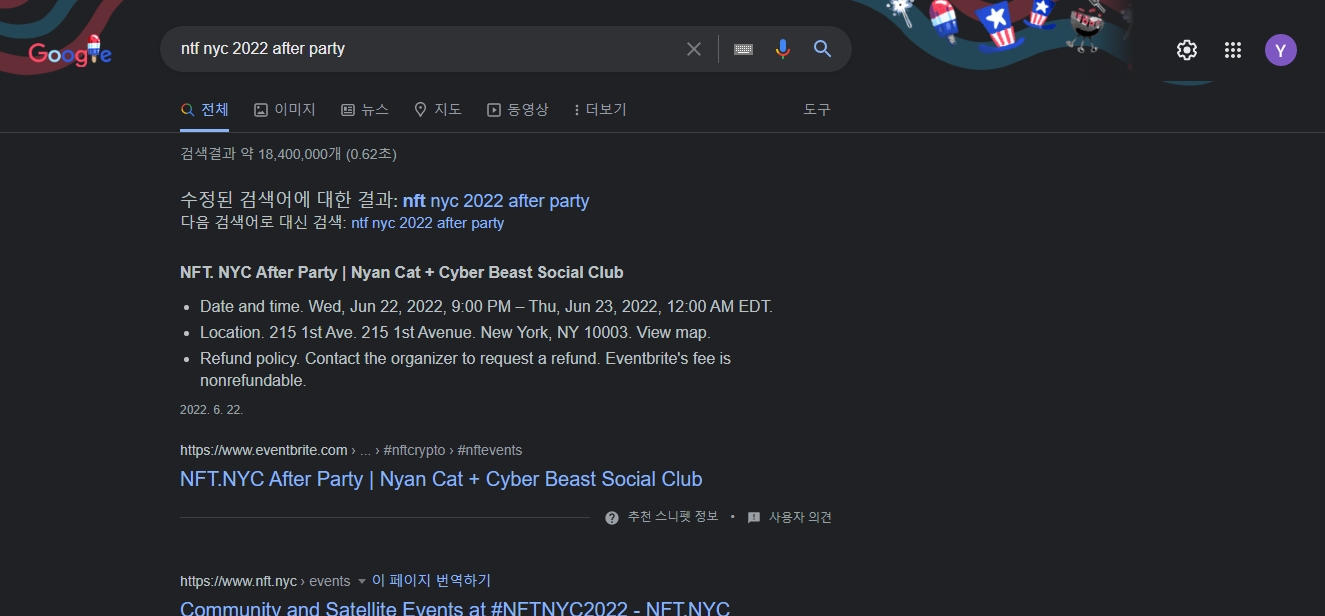
실행결과를 보면 nft nyc 2002 after party 를 넣고 검색한 결과 가 날것 그대로 나온다. 우리가 원하는 결과는 뉴스 검색 결과인데, 뉴스 뿐 아니라 일반 검색 결과까지 다 나오는 것이다. 그럼 이것만 가지고는 원하는 결과를 얻을 수 없다고 판단할 수 있다.
파라미터들을 한땀한땀 확인해 본 결과 다음이 원하는 결과를 얻을 수 있는 가장 간단한 url이다.
https://www.google.com/search?q=nft+nyc+2022+after+party&tbm=nws&start=0
https://www.google.com/search 는 구글링을 위한 기본 주소이고, q는 검색 키워드, tbm은 뉴스섹션, start는 페이지 번호를 의미한다. 일단 크롤링할 대상 url을 저장한다.
url = 'https://www.google.com/search?q=ntf+nyc+2022+after+party&tbm=nws&start=0'이제 requests 라이브러리를 이용해 url의 내용을 가져올 차례다. requests의 get() 함수를 이용해 requests.get(url) 과 같이 적고 실행하면 해당 페이지의 소스를 가져온다.
그런데 대부분의 웹사이트는 자신들의 정보를 쉽게 크롤링 당하게 방치하지 않는다. 크롤러를 최대한 귀찮게 해서 쓸데없는 트래픽 유발을 막고싶어 한다. 그래서 봇이 크롤링 하려 하면 비정상적인 페이지 정보를 돌려준다. 이런 이유로 난 봇이 아니에요 라고 가장하는 정보를 함께 넣어서 크롤링 해줘야 한다. 이는 브라우저의 헤더 정보로 넣어준다.
h = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.57',
'X-Requested-With': 'XMLHttpRequest',
}
r = requests.get(url, headers=h)이 코드의 핵심은 requests.get(url) 이지만, 구글에게 정상적인 소스코드를 받기 위해 url 뒤에 headers 정보를 추가했다. headers 정보는 h에 담아 보냈는데, 자신이 사용하는 웹브라우저의 헤더값을 복사해 넣으면 된다. 브라우저의 헤더값을 가져오는 방법은 따로 안내한다.
가지고 온 결과값은 변수 r에 저장했는데, r을 출력해보면 <Response [200]>이 출력된다. Response 객체로 결과값을 돌려받았다는건데, 중요한건 그 안에 들은 실제 값이다. 그걸 보려면 r.text로 출력해보면 된다.
r.text<!doctype html><html itemscope="" itemtype...
출력결과 html 소스코드가 문자열로 들어있음을 확인할 수 있다.
이제 r.text를 해석하고 그 안에서 우리가 필요한 값을 찾아내야 한다. html 코드를 해석할 때 이용하는 것이 BeautifulSoup 이다.
soup = BeautifulSoup(r.text, 'lxml')BeautifulSoup() 함수 안에 r.text를 넣어 해석을 시키는데, 문자열 해석(parsing) 방식으로 'lxml'을 지정해준다. 파싱을 위한 여러가지 옵션은 별도로 안내한다. BeautifulSoup()으로 해석한 내용은 변수 soup에 저장한다.
soup을 출력해보면 아까와 마찬가지로 긴 html 코드가 들어있다. 사람 눈으로 보기엔 아까랑 달라진게 뭐임 할 것이다. 하지만 컴퓨터 입장에서는 많이 달라졌다. r.text에는 아무 의미 없는 긴 문자열이 들어있었지만, soup에는 각 태그별로 발라낸 값들이 들어있기 때문이다. 이제 soup에서 태그 사이를 헤집고 다니며 원하는 값을 찾아낼 수 있다. 예를들어 soup.find_all('a') 라고 하면 <a> 태그 전체가 출력된다.
soup.find_all('a')[<a href="/search?q=ntf+nyc+2022+after+party&tbm=nws&gbv=1&sei=Zi3DYobQJdjZkPIP-o6L2AM">here</a>,
<a class="gyPpGe" data-ved="0ahUKEwiGm4zc6t_4AhXYLEQIHXrHAjsQ67oDCAU" jsaction="i3viod" jsname="BKxS1e" role="link" tabindex="0">Skip to main content</a>, ...
앞서 검색결과 분석을 하면서 검색결과 내용은 <div id="search">에 들어있는 것을 알았다. 이 부분을 찾아보자.
soup.find_all('div', id='search')검색결과 부분만 출력이 됐지만 여전히 너무 많다. 이제 분석한 내용을 조금씩 더 적용해보자. 검색 결과를 더 파고들자. 마찬가지로 앞서 분석한 내용을 적용한다. 각각의 기사는 <div class="xuvV6b ... 로 시작하는 태그에 담긴것을 위에서 확인했었다. 본문 코드 뒤에 아래와 같이 덧붙인다.
rst = soup.find_all('div', id='search')[0].find_all('div', class_='xuvV6b')이제 rst에는 검색 결과들이 담긴 리스트가 들어있다. 이제 이 검색 결과에서 제목과 링크주소를 가져올 차례다.
이 리스트의 원소를 하나씩 순회하며 제목과 링크를 뽑아보자.
html에서 하이퍼링크는 <a> 태그에, 제목은 <div role="heading">에 들어있는 것을 위에서 확인했다. 이들을 발라내는 코드다.
for r in rst:
print(r.find("div", {"role" : "heading"}).text.replace("\n",""))
print(r.find("a").get("href"))NFT.NYC 2022: what is it and who should I watch?
https://www.creativebloq.com/news/nft-nyc-2022
The World's Biggest NFT Festival vs. the Crypto Crash of 2022
https://www.cnet.com/personal-finance/crypto/the-worlds-biggest-nft-festival-vs-the-crypto-crash-of-2022/
Vibe Check: What Was NFT NYC Like Amid a Bear Market?
https://decrypt.co/104111/vibe-check-what-was-nft-nyc-like-amid-a-bear-market
NFT.NYC 2022: The Ultimate Guide
https://nftevening.com/nft-nyc-2022-the-ultimate-guide/
'We're Poor Again, but We're Still Here': Why NFT.NYC Won't Die
https://www.coindesk.com/tech/2022/06/24/were-poor-again-but-were-still-here-why-nftnyc-wont-die/
A Tale of Two NFT Parties: Doodles vs. Goblintown
https://decrypt.co/103848/a-tale-of-two-ethereum-nft-parties-doodles-goblintown
Crypto Reacts To The NFT NYC Conference: The Bad And The Ugly | Bitcoinist.com
https://bitcoinist.com/crypto-reacts-nft-nyc-the-bad-and-the-ugly/
If NFT.NYC Represents the Future of Art, Then Why Was It So Boring?
https://news.artnet.com/market/why-was-nft-nyc-so-boring-2136620
NFT.NYC Brings New Technology And Old DJs To Town
https://www.forbes.com/sites/ericfuller/2022/06/30/nftnyc-brings-new-technology-and-old-djs-to-town/
Somewhere Nowhere, Powered by SWNW Lab, is the ...
https://www.businesswire.com/news/home/20220617005505/en/Somewhere-Nowhere-Powered-by-SWNW-Lab-is-the-Nightlife-Destination-of-NFT.NYC-2022
rst에 들어있는 각 원소 r을 순회하며 role="heading"인 <div>를 뽑아 제목으로 출력하고, <a>를 뽑아 href링크를 출력한다. 크롤링 완료. 이제 이들을 필요에 따라 활용하면 된다.
지금까지 nft nyc 2022 after party 라는 키워드로 검색된 뉴스 결과를 크롤링 했다. 여기에서는 딸랑 한페이지만 한거라 크롤링 봇이라 부를 수준까지는 안된다. 자동화된 봇이라면 페이지를 넘겨가며 필요한 정보를 싹 긁어와야 한다. 이는 페이지를 넘어가는 부분을 구현해야 하는데, 분량이 좀 되니 별도의 글로 소개하겠다.
'파이썬' 카테고리의 다른 글
| 텔레그램 봇 메시지 보내기 (2) | 2022.09.17 |
|---|---|
| 메이저리그 기록 크롤링 (baseball-reference.com) (1) | 2022.07.26 |
| 파이썬의 클래스 (1) | 2022.06.22 |
| 파이썬의 함수 (0) | 2022.06.22 |
| 데이터프레임에서 인덱스값을 기준으로 최종 열을 뽑을때 (2) | 2022.06.16 |



